
We are going to build a exam portal using Canvas Apps. Our datasource is going to be an excel sheet that is hosted on OneDrive business account. Your datasource can be of your choice like sharepoint list, sql server etc.
Our datasource consists of four tables, exam, questions, options, and results.

Exam Table has two columns. Id and Exam.
Id – Unique Identifier
Exam – Name of Exam

Questions Table has 4 columns. Id, QuestionNumber, Question, ExamId.
Id – Unique Identifier
QuestionNumber – Question Number in that particular Exam.
Question – Question Description
ExamId – Which Exam does this question belong to?

Options table has 4 columns. Id, Answer, IsCorrect, QuestionId.
Id – Unique Identifier
Answer – Option Description
IsCorrect – Marking which answer is correct
QuestionId – Which Question does this option belong to?

Results table has 6 columns. User, UserEmail, Score, ExamName, ExamId, JsonObject. User – User Name
UserEmail – User Email
Score – Score of a user for a particular Exam
ExamName – Name of the Exam
ExamId – Id of the Exam
JsonObject – User Data that is used to capture Selected Options for a question, calculate score and also understand how user has performed in Exam.
Upload this file to OneDrive and create a Power Apps Canvas Application from Blank in Power Apps Portal. Establish a connection to your OneDrive account and connect to all the four tables.

Create two Screens Home and Exam, Home screen will have all the exams which user can take, and Exam Screen will have questions and exam once user selects his desired Exam. In Home Screen, create a blank vertical gallery and bind the Exams Datasource.

Edit Gallery and Insert Button with Text property set to ThisItem.Exam which populates Exam Name on Buttons.

On the OnSelect Action of the Gallery Apply the following code –
Navigate(Exam,ScreenTransition.Fade, {selectedexam: ThisItem})
Navigating to the Exam Page and creating a context variable in Exam page called selectedexam and passing in the selected exam using ThisItem. In Exam page create a label and change it’s Text Property to selectedexam.Exam to show the heading of the Exam. Design the page with Question – 1 Label that shows the Question Number and then two Icons right and left to go to next and previous questions respectively, a finish button once user wants to finish the exam.

Now, Exam Screen has a action called OnVisible which gets triggered once the Exam Screen is Visible. Fetch the first question and options for that question of the Selected Exam by using the following code:
UpdateContext({question: First(Filter(Questions, ExamId = selectedexam.Id))});
ClearCollect(option, Filter(Options, QuestionId = question.Id));
You now have the first question and it’s options in selected exam, update the Question number label’s Text property as
“Question - ” & question.QuestionNumber
And question label’s Text Property as question.Question
Now for options select an empty vertical Gallery and bind the datasource with the option collection we have created.
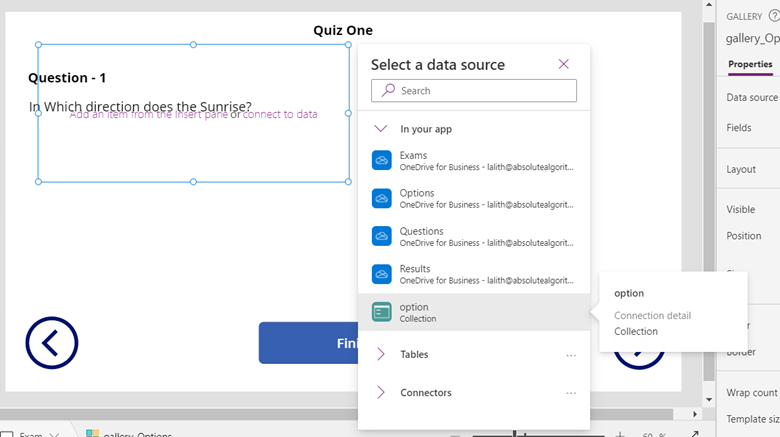
Edit the gallery and insert a checkbox with the its next label set to ThisItem.Answer to display answers

All our questions have only one correct answer, so we should let user select only one checkbox and not multiple check boxes. To do this we start with creating a label to count the number of check boxes that are selected.

Upon selecting the checkboxes the count label will increment and decrement the values.

Turn off the visible property of the count label and In Checkbox DisplayMode write the following code:
If(Self.Value || Value(label_CountSelectedOptions.Text) = 0, DisplayMode.Edit, DisplayMode.Disabled)
This code will ensure that only one checkbox is selected at once. You might think to Count the Selected number of Checkboxes directly in the display mode of the Checkbox, but you will not get the access to the other checkboxes as we are creating them with gallery.

Now, we must fetch previous question and its options upon clicking previous icon. Next question and its options upon clicking next icon. but previous icon should be disabled if we are on the first question and next question should be disabled if we are on the last question. To help us with all this functionality we are going to declare more variables in our Exam’s Screen OnVisible action

questioncount – to get the number of questions in the selected exam
questionid – get the question id of the selected question
firstquestionid – get the first question id of the selected exam
Now, update the next icon’s OnSelect action with the following code:

You can see that we are incrementing the value of questionid when the current question that is being displayed is less than the questioncount. Then we are fetching our new question and its respective options with the help of questionid.
We disable the next icon if quesionnumber is not less than the questioncount so that we do not go out of the bounds of this exam.

Similarly, we update the previous icon’s OnSelect action with the following code:

Here, we are decrementing the questionid as long as the current questionid is greater than the first question’s id. We then use the questionid to fetch the question and its options.
We now disable previous question icon when questionid is not greater than the firstquestionid

Now we can easily go through all the questions that are from the selected exam using the next and previous icons. We now must capture all the selected options by user and also calculate the score. To do this we are going to introduce a new collection variable called jsonobject on Exam’s OnVisible Property.

We are capturing the questionid, selectedoption and if it is correct or wrong. By default we will be having selectedoption as empty string and iscorrect as false. All this happens for the first time when user loads the exam. we now have to get data for the selectedoption and also if it is correct. We do that by introducing a new variable called selectedOption on the OnCheck action of checkbox_Options

we must update the selectedOption to blank when the particular checkbox is unchecked. Imagine a situation where user first selects a checkbox (we will update the selectedOption). Now user unchecks the checkbox, doesn’t select any other option and goes to previous or next question. selectedOption will still be the first checkbox which the user has selected which will cause a problem when we update our jsonObject in our next code.

We must capture the user’s selectedoptions in jsonObject to calculate the score. So, update the next’s icon OnSelect action with following code:

Now there are two new things which are added to the next’s icon OnSelect action. First we Patch the jsonObject updating the current questionid object from the jsonObject collection, we update selectedoption and iscorrect properties. Then we change the questionid and get the new question and option details. We then check if jsonObject collection holds a new object that is used to track this newly updated question and if not we will add a new record to the jsonObject collection with the new questionid and by default selectedoption as empty string and iscorrect as false. We update the same code in the previous icon’s OnSelect action to patch jsonObject. Once you are done answering all the questions the jsonObject will now be something like this:

our checkboxes are not able to retain the previously selected option by user when you go previous and next a few times. We can do this by changing the default property check boxes with the following code by using the jsonObject collection

Everything till here looks perfect, but we still have a problem, our checkboxes start acting weird and will not be able to still retain the selected options by the user. This problem is because jsonObject will be patched with empty selectoption and iscorrect as false though the user has provided correct options and just skimming through questions before finishing the exam. To address this issue we have to update our code. Create a new variable called answerSelected which is true on the OnCheck action of the check box.

Now, on update the OnUnCheck action with the following code:

We are making answerselected as false and also we have introduced a new variable to capture if a question is already answered and now unchecked.
We now update the pathing of our jsonObject with the following code:
If(answerSelected || alreadyAnsweredandUnChecked, Patch(jsonObject, LookUp(jsonObject, questionid = question.Id),{selectedoption: If(selectedOption.QuestionId = question.Id, selectedOption.Answer, "")}, {iscorrect: If(selectedOption.QuestionId = question.Id && selectedOption.IsCorrect = "1", true, false)}), false);
So, we patch our jsonObject only if it is answered or alreadyAnsweredandUnChecked. We update this code in next and previous icons.
Finally, our exam starts behaving as expected and now we are left with Finish button’s functionality. Update the OnSelect Action of Finish button with the following code:

You observe me doing the patching of jsonObject here as well, the reason for that is we must capture the data no matter on whatever question the user decides to finish his exam. it might be on question 2 while there are 4 or 5 questions in the exam. we finally patch Results with a new record calculating score and sending the jsonObject in Json format just in case if you want to show the user’s performance and for the admin to cross verify if the score has been calculated properly. Open, excel workbook Result’s table and you will be able to see the following:

You can find this project on GitHub
For details on our upcoming courses and webinars, Visit @https://www.bestdotnettraining.com/courses-and-webinars
To always stay up-to-date with our free webinars and course with our WhatsApp Tech Group, Join now!
For any Query,
Mr. Lalith Prasad
Mobile/WhatsApp Number: +91 97011 18218
Email: lalith.p@deccansoft.net


